Right Triangle For Finding Distance Across a River
| View Cart ⇗ | Info
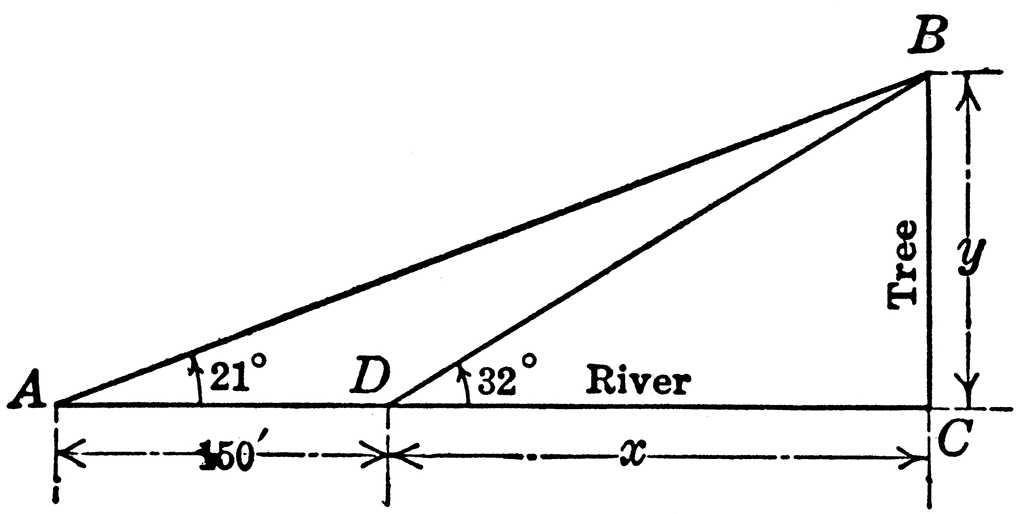
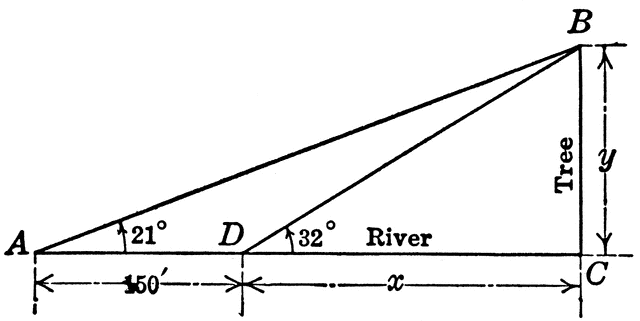
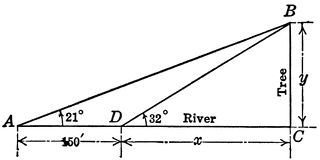
Right triangle ABC with angles A, B, C to be used for finding distance across a river. This is a trigonometry problem. Wishing to determine the width of the river, I observed a tree standing directly across on the bank. The angle of elevation of the top of the tree was 32 degrees. At 150 ft. back from this point and in the same direction from the tree the angle of elevation of the top of the tree was 21 degrees. Find the width of the river.
Keywords
tree, cross, river, c, a, b, triangles, Right Triangle, Problem, trigonometry, width, trig, crossing, distance across, angle of elevationGalleries
Trigonometry: TrianglesSource
Claude Irwin Palmer Library of Practical Electricity: Practical Mathematics For Home Study (New York: McGraw-Hill Book Company, Inc., 1919) 432
Downloads
2400×1206, 143.9 KiB
1024×514, 24.1 KiB
{kind=link}
640×321, 14.8 KiB
{kind=link}
320×160, 6.4 KiB